DBSCAN?(1)
DBSCAN
정의
DBSCAN은 Density-Based Spatial Clustering of Applications with Noise의 약자로 핵심 데이터(Core Point)를 중심으로 밀도가 높은 곳에 포함된 데이터일 경우 클러스터링을 진행하고 밀도가 낮은 곳에 포함된 데이터를 노이즈로 판단하는 알고리즘이다. 간략히 말해 밀도 기반의 군집화 알고리즘이라는 의미이다.
K-Means 알고리즘과 DBSCAN의 차이
단순히, DBSCAN의 정의만 보았을 때 K-Means 알고리즘과 큰 차이를 못 느낄 수 있다. 그림을 통해 차이를 알아보도록 하자.
다음과 같이 데이터가 분포되어 있다고 가정하자.

해당 데이터에 K-Means 알고리즘을 적용하여 클러스터링을 진행하게되면 가상의 점1, 점2를 기준으로 하여 거리적인 정보만을 가지고 클러스터링을 진행하게 된다. K-Means 알고리즘을 적용한 후 데이터 분포는 다음과 같다.

하지만, 하이라이팅된 부분은 어색한 부분이 존재하며, 가장 이상적인 클러스터링은 아래와 같이 거리가 가까운 데이터끼리 클러스터링되는 것이다.

K-Means 알고리즘을 적용하여 클러스터링을 진행하였을 때 왜 어색한 부분이 존재할까?
K-Means 알고리즘은 특정 선(가상)을 기준으로 하여 거리가 가깝고 먼 정도에 의해 클러스터링을 진행하기 때문에 위와 같은 어색한 부분이 발생한다. 즉, 데이터들의 밀도는 제대로 반영하지 않는다는 것이다.
DBSCAN 알고리즘은 K-means알고리즘의 단점을 보완할 수 있는 알고리즘으로 데이터의 밀도를 반영하기 때문에 이상적인 클러스터링이 가능해진다.
동작 방식
DBSCAN 알고리즘은 첫번째 단계로 핵심 데이터(Core Point)와 비 핵심 데이터(Non-Core Point)나누게 된다. 이때 구분하는 지표는 반경의 크기(=eps)와 최소 군집의 크기(=최소 샘플 수, MinPts)로 사전에 정해야 한다.
반경의 크기란 얼마나 가까워야 연관성이 있다고 판단할 것인지, 연결되었다고 볼 것인지에 대한 값이고 최소 군집의 크기는 반경 내 최소 몇개의 데이터가 존재해야 클러스터로 볼 것인가에 대한 값이다.
그렇다면, 특정 데이터 몇 개가 특정 반경 내 위치한다면 데이터 중 1개를 핵심 데이터로 볼 수 있을까? 답은 그렇지 않다이다. 핵심 데이터로 판단하기 위해서는 우리가 설정한 반경의 크기 내 최소 군집의 크기(최소 샘플 수)만큼 데이터(샘플)이 존재해야 한다.
다음과 같은 데이터 분포가 존재하고 반경의 크기를 아래 그림에 존재하는 원, 최소 군집의 크기를 3으로 가정하자.

위 데이터 분포를 핵심 데이터와 비 핵심 데이터로 구분한 후 1번째 클러스터 할당까지 진행하면 다음과 같은 모습을 보인다. 반경 내 최소 군집의 크기를 만족한다면 핵심데이터, 만족하지 않는다면 비 핵심데이터로 판단한다.

1단계 클러스터 할당 완료 후 비 핵심 데이터를 반경 내 핵심데이터가 존재한다면 해당 핵심데이터의 클러스터로 할당한다. 위 과정을 더 이상 할당 가능한 비 핵심 데이터가 존재하지 않을 때까지 반복한다.
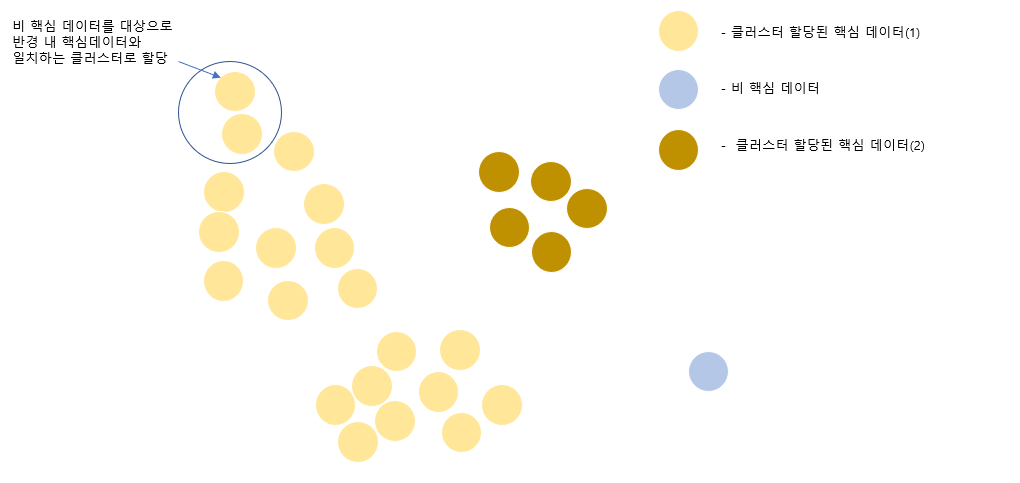
2단계 클러스터 할당 이후 우리가 원하던 이상적인 형태가 나온 것을 확인할 수 있다. 하지만, 오른쪽 끝에 존재하는 비 핵심 데이터는 어떻게 될까? 반경 내 핵심 데이터가 존재하지 않기 때문에 특정 클러스터로 할당할 수 없다. DBSCAN는 이러한 데이터를 노이즈로 판단하게 된다.

DBSCAN의 특징 및 장점
1.클러스터의 개수를 미리 지정할 필요가 없다.
DBSCAN 알고리즘은 우리가 사전에 지정한 반경의 크기와 최소 군집 수에 따라 핵심 데이터와 비 핵심 데이터를 구분하고 클러스터 할당을 자동으로 진행하기 때문에 클러스터의 개수를 미리 지정할 밀요가 없다. 또한, 더 이상 할당 가능한 핵심 데이터가 존재하지 않을 경우 알고리즘은 종료된다.
2.노이즈(이상치)를 효과적으로 제거할 수 있다.
비 핵심 데이터 중 반경 내 핵심 데이터가 존재하지 않을 경우 자동으로 노이즈로 판단하게 된다. 즉, 데이터 밀도가 충분히 반영되게 되고 비교적 밀도가 떨어지는 노이즈 데이터에 대한 효과적인 제거가 가능하다.
3.반경의 크기와 최소 군집 수를 적절하게 변화시켜 여러 형태의 클러스터 패턴 확보가 가능하다.
지정하는 반경의 크기와 최소 군집 수에 따라 클러스터 할당 형태가 변하기 때문에 여러 형태의 클러스터 패턴 확보가 가능해진다.
Reference
 https://pizzathief.oopy.io/dbscan
https://pizzathief.oopy.io/dbscan

코드 구현 및 수식과 관련된 내용은 다음 장에서 포스팅하도록 하겠습니다🙂
오류, 잘못된 점 또는 궁금한 점이 있으시다면 댓글 남겨주세요❗
Uploaded by N2T